A magyar diákokat már lehagyta a mesterséges intelligencia

-
24.hu - Tech
- 12 Mar, 2025
- Címkék: #Tech # kompetenciamérés # magyar diákok # mesterséges intelligencia # oktatás
Az Oktatási Hivatal adatai szerint az elmúlt években a legtöbb korosztályban csökkenést mutattak, néhol pedig egészen konkrétan zuhanórepülésbe kezdtek a diákok országos kompetenciaméréseinek eredményei. Az alapvetően hatodikos, nyolcadikos és tizedikes diákok matematikai és szövegértési képességeit vizsgáló teszten 2019 óta szinte folyamatos a visszaesés, de persze nem minden korosztályban és területen ugyanolyan mértékben.
A nyolcadikos diákok szövegértési képességeiben 5 év alatt 9,5 százalékos visszaesést lehetett megfigyelni, és a szövegértési kompetenciák tekintetében is ebben a korosztályban romlott leginkább a helyzet.
A hatodikosoknál a legkisebb a visszaesés, ám még így is szemmel látható: itt az átlagot tekintve 2 százalékkal rosszabb matematikai és 6,7 százalékkal rosszabb szövegértési eredményekről beszélhetünk.
A kompetenciamérés lényege, hogy a tanulók általános képességét vizsgálja meg olyan kérdések révén, amelyekre nem feltétlenül találják meg a választ a tankönyvekben. Az életből átemelt példák megoldása kapcsán tapasztalható, egyre romló tendencia több mindenre rámutathat: az oktatási rendszer hatékonytalanságára, a szociális háttér tanulókra gyakorolt hatására, valamint a fiatalabb generáció tanulási nehézségeire, csak hogy néhányat említsünk.
EMS-FORSTER-PRODUCTIONSKönnyedén lehet továbbá, hogy a technológia adta kényelem is szerepet játszik ebben: mára ugyanis minden diák számára, aki rendelkezik okostelefonnal, elérhetővé váltak az akár ingyenes mesterségesintelligencia-szolgáltatások, melyek sokak szerint már képesek megbirkózni az iskolai feladatokkal. A Peak nevű fintech cég mesterséges intelligenciára specializálódott üzletágának kutatása annak járt utána, hogy az egyes MI-modellek tényleg képesek-e lepipálni a magyar diákokat. A csapat 70 szövegértési és 70 matematikai feladatot használt az MI-modellek tesztelésére.
Okosabb az MI, mint egy egy tizedikes?
A legnagyobb techcégek évente akár több milliárd dollárt is elkölthetnek különböző nyelvi modellek (LM) képzésére: a Meta például csak idén 65 milliárd dollárt tervez erre a célra fordítani, még sincs ott a piacvezető fejlesztők között. Jelenleg egyértelműen az OpenAI, a Google és az Anthropic diktálják a ritmust, és bár ezen cégekre rá tudott ijeszteni a kínai DeepSeek, rövid időn belül kiderült, hogy a rendszer valójában közel sem olyan hatékony, mint állították, és az adatait is nagyrészt az OpenAI chatbotjától „tanulta el”.
A mesterséges intelligencia modellek mérése, osztályozása napjainkban egy igencsak megosztó témakör, ugyanis sokféle benchmarkteszt érhető el a piacon. Ezek közül négyről lehet azt mondani, hogy a legmegbízhatóbb: az MMLU, a GPQA, a MATH és a HumanEval. Az első több mint 16 ezer feleletválasztós kérdést tartalmaz, míg a GPQA olyan kérdéseket tesz fel a modelleknek, amilyenekre nem lehet rákérdezni direktben a Google-ben. Utóbbi kettő inkább a reálképességeit vizsgálja az LM-eknek, a MATH a matematikai, míg a HUMANEVAL a kódolási képességeket.
A PeakX csapata annak érdekében, hogy letesztelje, le tudja-e győzni a diákokat a kompetenciamérésben egy MI-modell, a benchmarktesztek alapján legjobbnak tartott és legismertebb modelleket hívta segítségül.
Ahhoz, hogy mérhetők legyenek a képességeik, a csapat felépített egy úgynevezett MI-ügynököt (AI agent) az OpenAI megoldása alapján, ami felteszi a kérdéseket, egy másik ügynök pedig kiértékeli a nyelvi modell által adott feleleteket. Ez a vizsgálat szépen rávilágított, hogy melyik modell miben jó igazán, és hogy melyek azok a területek, ahol még fejlődniük kell.
Zongorázható a különbség
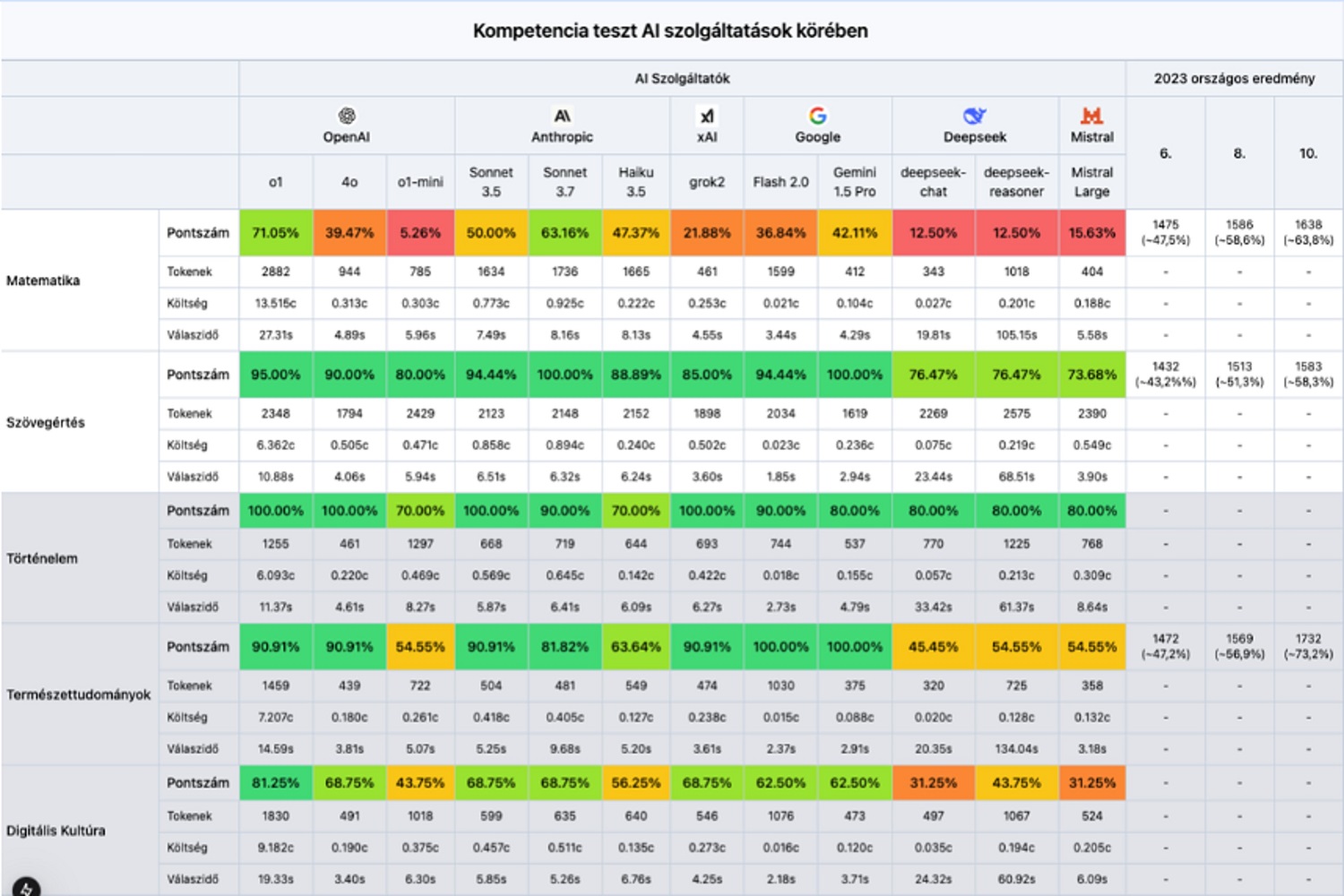
A Peak kutatása rámutatott, hogy nem véletlenül piacvezető az OpenAI: a cég o1 mevű modellje messze a legjobb eredményt mutatta fel a matematikai kompetenciamérés esetében, ami meghaladta a 70 százalékot. A kompetenciateszten az o1 a lehetséges pontok 70,59 százalékát szerezte meg. Csak viszonyításképp: a 2023-as kompetenciamérésen a hatodikos tanulók 47,5 százalékot, a nyolcadikosok 58,6 százalékot, míg a tizedekesek 63,8 százalékot értek el átlagosan.
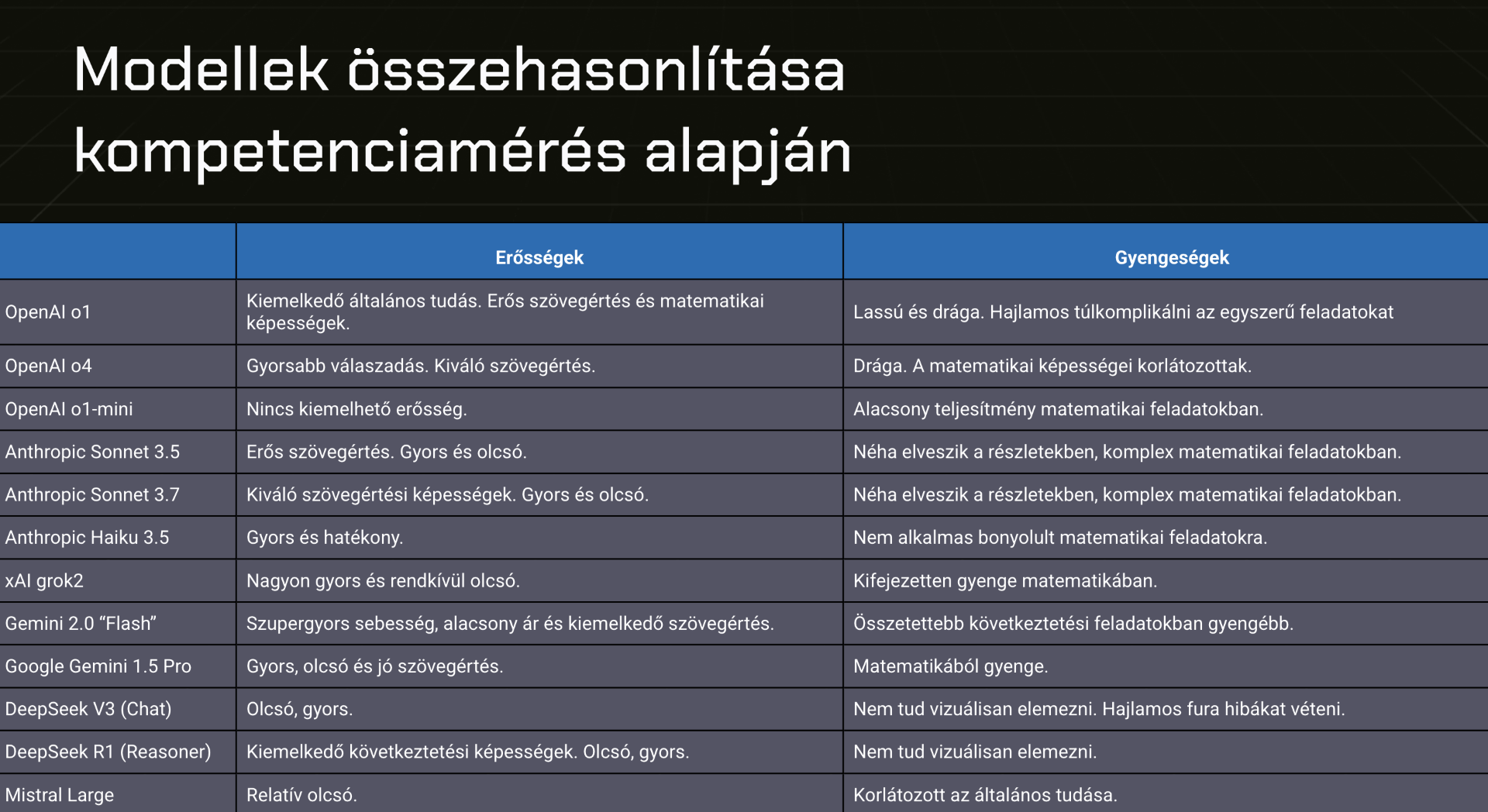
Az OpenAI legfejlettebb modelljének eredményei messze kimagaslanak a többi fejlesztés közül: egyedül az Anthropic vállalat Sonet 3.7-je teljesített még 60 százalék fölött, ráadásul sokkal gyorsabban és olcsóbban dolgozott, mint az OpenAI modellje. A matekból legrosszabb megoldások (Deepseek: 12,5 százalék, OpenAI o1 mini 5,26 százalék) azonban messze elmaradtak az iskolások eredményeitől, így jól látható, hogy a matematikai feladatokban közel sem működnek még hibátlanul az MI-modellek.
Szövegértés terén azonban már teljesen egyértelmű a kép. Míg a 2023-as mérés eredményeinek átlaga a hatodikosoknál 43,2, a nyolcadikosoknál 51,3, a tizedikeseknél pedig 58,3 százalék volt, addig a nyelvi modellek közül még a legrosszabbul teljesítők is bőven 70 százalék felett teljesítettek. Egészen pontosan a francia Mistral 73,68, míg a DeepSeek 76,47 százalékot ért el.
Az Anthropic sonnet 3.7 és a Google Gemini 1.5 pro modellje pedig 100 százalékot produkált. Ebből az is jól látható, hogy az amerikai modellek dominanciája egyelőre megkérdőjelezhetetlen: a Mistral és a Deepseek ugyanis matekban és szövegértésben is jóval elmarad a konkurensek eredményeitől.
A PeakX a természettudományok területén is összemérte a diákok eredményeit a nyelvi modellekével, az eredmények alapján pedig néhány kivételtől eltekintve itt is az MI diadalmaskodott.
Tanulságok
A fintech cég MI-re specializálódott vállalatának kutatásából egyértelműen kiderül, hogy míg az érvelő (reasoning) modellek lassabbak és drágábbak, minden kategóriában jobb eredményt értek el, mint a többi modell. Az eredmények azt mutatják, hogy a nagy nyelvi modellek a problémamegoldó és analitikus készségeket igénylő területeken még nem képesek egyértelműen helyettesíteni az embereket. Különösen a komplex matematikai készségeket igénylő feladatoknál mutatkozik meg lemaradásuk.
PeakXSzületett azonban még néhány fontos megállapítás: például az, hogy a benchmarkmetrikák túlzottan optimisták, ugyanis a való életbeli teszteken érezhetően rosszabb eredményeket hoztak, mint laboratóriumi körülmények között készülteknél. Vannak olyan modellek is, amelyek még mindig nehezen birkóznak meg a vizuális ingerekkel, a szakértők szerint nagyjából úgy, mintha az ember homályosan látna.
A szakértők emellett arra is felfigyeltek, hogy a magyar nyelvvel és a hazai kulturális kontextusú kérdésekkel is meggyűlt a modellek baja.
Kiderült továbbá, hogy néhány kivételtől eltekintve a modellek nem tudnak végigfuttatni egy gondolatsort anélkül, hogy megzavarodnának, és sűrűn el is akadnak. A mostani fejlesztéseknél tehát komplexebb modellekre lesz szükség ahhoz, hogy hibátlanul tudják teljesíteni a kompetenciateszteket. A magyar diákok átlagánál azonban már most jobban teljesít a legtöbb mesterséges intelligencia.
The post A magyar diákokat már lehagyta a mesterséges intelligencia first appeared on 24.hu.
Hasonló tartalmak



{kind=link}
{kind=link}
{kind=link}
 Hirdetés
Hirdetés